Chytrá domácnost, hlasové ovládání OffLine Home Assistant. — DRIVE2
Nedávno jsme představili náš nový chytrý reproduktor – Yandex Station Midi. Je větší než Light nebo Mini, takže obsahuje woofer a dva vysokofrekvenční reproduktory s celkovým zvukovým výkonem 24 W. Zároveň je ale lehčí a skladnější než Station 2 nebo Max. Navíc jsme v Midi představili technologie, které Alici umožnily učit se nové věci. Zejména díky modernějšímu procesoru a většímu množství paměti RAM začala Alice in the Midi Station poprvé rozumět a provádět hlasové příkazy chytré domácnosti lokálně, bez internetu. To je příležitost, na kterou se dnes zaměříme.
Dnes vám stručně prozradíme, jaké úkoly musel tým Alice a chytrých zařízení vyřešit, aby uživatelé mohli ovládat zařízení kompatibilní se Zigbee pomocí svého hlasu a nebyli závislí na vzdáleném serveru nebo poskytovateli.
O lokální chytré domácnosti jsme se poprvé začali bavit na jaře tohoto roku. Možná jste dokonce četli článek o Habrovi o tom, jak jsme naučili naše reproduktory s vestavěným modulem Zigbee ukládat a spouštět scénáře chytré domácnosti přímo, bez prostředníka v podobě serveru. Ale byla tu omezení: fungovalo to pouze pro ty scénáře, které byly spuštěny tlačítkem nebo časovačem. Protože práce s hlasovými příkazy byla dostupná pouze přes náš cloud. To byl pro železo příliš obtížný úkol.
Vraťme se k nové Midi Station. Možná vám někdy prozradíme, jak se nám do relativně kompaktního pouzdra podařilo vměstnat zakázkovou akustiku, LED podsvícení, displej a veškerou další elektroniku, ale dnes nás zajímá něco jiného – nová výpočetní jednotka, přesněji SoC A113×2 od Amlogic s dedikovaným NPU, dále 1 GB RAM a 8 GB flash paměti (pro srovnání: u flash paměti máme 256 MB256 Mini). Není to špatná rezerva výpočetních zdrojů pro tuto třídu zařízení. Bez něj bychom naše plány nemohli realizovat. Samotné zdroje však nestačily. Museli jsme přehodnotit, co bylo vytvořeno pro provoz na serveru.
Zpočátku byl proces práce s chytrou domácností součástí procesu Alice in the Cloud. Abychom však dosáhli lokality, museli jsme opatrně přesunout tři po sobě jdoucí komponenty zodpovědné za chytrý dům do samostatného potrubí na zařízení. A přitom se v cloudových scénářích nic nezlomí. Na níže uvedeném diagramu můžete vidět komponenty, které měly fungovat lokálně.
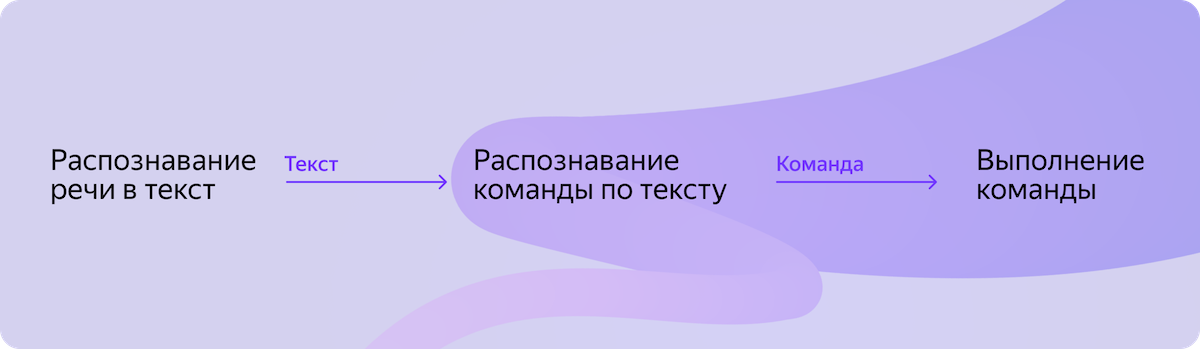
A všechno by bylo v pořádku, ale byla tu nuance. Žádná z těchto komponentů připravených k použití pro nás v minulosti neexistovala. To znamená, že musely být vytvořeny.
Rozpoznávání řeči na text
Nejzřetelnější věcí je, že potřebujeme neuronovou síť, která rozpozná hlas na text přímo na zařízení. S dobrou kvalitou. A zároveň pracovat ne na nejvýkonnějším superpočítači v Rusku, ale na malém SoC, které sdílí velmi omezený životní prostor s dalšími užitečnými věcmi. Nic složitého, že?
Nejprve si povíme, jak funguje naše cloudové ASR. Zjednodušeně řečeno se jedná o tři neuronové sítě. První z nich mění proud na slova za běhu, aniž by čekal na dokončení celé fráze. To je užitečné, aby uživatelé mohli okamžitě vidět svůj dotaz v rozhraní, když jej vyslovují. Proto je tato neuronová síť na serverové standardy rychlá a relativně lehká (pouze několik set milionů parametrů).
Druhá neuronová síť pracuje v tandemu s první a jejím jediným úkolem je předpovědět okamžik, kdy fráze skončí.
Po dokončení repliky je celá fráze odeslána na vstup největší, třetí neuronové sítě. Funguje pomaleji, ale kvalita rozpoznávání libovolných frází je vyšší. A právě výsledek práce třetí neuronové sítě je považován za konečný.
Ale sloupec není cluster s mnoha GPU. Nemůžeme si dovolit vměstnat do něj více modelů serverů. Ani jedno neumíme. Začali jsme přemýšlet, kde bychom mohli ušetřit zdroje. První výše popsaná neuronová síť ze serverového řešení, přestože dešifruje každé slovo za chodu, ve skutečnosti nefunguje v režimu streamování, ale znovu dešifruje celou frázi poté, co se objeví nový zvuk (možná jste si při kontaktování Alice všimli, že text požadavku se může zpětně změnit). To se děje záměrně. Každé nové rozpoznané slovo může pomoci neuronové síti upřesnit rozpoznávání předchozích slov díky kontextu dialogu. Například slovo „beat“ může být rozpoznáno jako „drink“ kvůli hluku na pozadí. Ale pokud je další slovo rozpoznáno jako „baklushi“, pak to umožní objasnit, že předchozí slovo bylo koneckonců „bit“.
Tento režim provozu však spotřebovává mnoho prostředků, protože každý nový zvuk v podstatě restartuje model. Pokud přejdete na poctivé streamování (rozpoznávání za běhu zohledňující minulost, ale ne budoucnost), můžete ušetřit. Ano, model bude fungovat o pár procent hůře, ale to je pro náš úkol celkem přijatelné (s ohledem na nedostatek zdrojů a zaměření na požadavky pouze z oblasti chytré domácnosti).
Provedli jsme testy s ohledem na přechod do režimu streamování. Pro nás bylo důležité, že model nejen fungoval na mluvčího, ale také rozpoznal řeč v text tak rychle, jak ji člověk vysloví. Rozhodli jsme se, že optimální bude zaměřit se na model s přibližně desítkami milionů parametrů. Navíc jsme potřebovali jediný model, který by rozluštil text a předpověděl konec fráze.
Pár slov o architektuře pro zájemce. Naše rychlá neuronová síť na straně serveru je založena na přístupu CTC. Tento přístup je sám o sobě docela kompatibilní se streamováním, ale kvalitu výsledku nejvíce ovlivňuje kodér (část neuronové sítě, která na vstupu převádí řeč na vektorovou reprezentaci). Vybrali jsme kodér s architekturou transformátoru – podle našich zkušeností v tuto chvíli nejlepší varianta. Jenže CTC v kombinaci s transformátorem v režimu streamování utrpělo poklesem kvality. Proto jsme se rozhodli nahradit CTC za RNN-T. Tento přístup ve spojení se stejným transformátorem v režimu streamování ukázal vyšší kvalitu rozpoznávání řeči.
Vyřešili jsme velikost modelu. S architekturou je to stejné. Nyní krátce o datové sadě. Trénink modelů probíhá v cloudu a tam takové problémy s výpočetními prostředky nejsou. Použili jsme datovou sadu, na které trénujeme cloudové modely ASR. Ovšem s řadou změn. Tou hlavní je, že jsme k ní přidali další ukázky z oblasti práce s chytrou domácností. Takto jsme neuronové síti „ukázali“, že právě tato sekce dotazů je pro nás obzvláště důležitá. Zároveň jsme z datasetu nevyškrtávali další kvalitní, originální příklady, protože na kvalitu má vliv i celková různorodost dat.
Výsledkem je, že jsme získali neuronovou síť, která se vešla do zařízení a dokázala převádět řeč na text v reálném čase v autonomním režimu.
Rozpoznejte příkaz podle textu
Máme tedy text uživatelské řeči. Nyní to musíme uznat jako tým chytré domácnosti. S ohledem na širokou škálu takových týmů. S pochopením názvů scénářů, které mohou být libovolné, protože je uživatel vymýšlí sám. A to s dobrou přesností, protože kromě příkazů pro chytrou domácnost existují i další scénáře, pro které je pro správné fungování potřeba odeslat požadavek do cloudu. Dalo by se říci, že jde o klasický NLU problém.
Yandex již dlouho dokáže vyřešit podobné problémy ve službách Search, Alice a mnoha dalších. Kolegové z vyhledávací infrastruktury například vyvinuli službu Begemot, která pomáhá porozumět dotazům a transformovat nestrukturovaný text do struktur srozumitelných pro další zpracování. Dobrou zprávou je, že tato služba je rychlá, protože byla vytvořena pro vyhledávání. Ale je tu jedna špatná (pro nás): tato věc funguje na infrastruktuře společnosti. Jedna instalace spotřebuje minimálně 30 GB RAM a další 30 GB flash paměti. Na stanici Midi prostě nebyla šance něco takového spustit. Bylo potřeba se přizpůsobit.
Jednoduše řečeno, Behemoth je mnoho a mnoho komponent, které tvoří graf zpracování uživatelských požadavků. Mohou to být například komponenty, které pomáhají najít geografické objekty v textu. Nebo data. Nebo Aliciny příkazy. Nejviditelnější možností je proto nasadit dietu: vzdát se všech komponent, které nejsou při práci s chytrým domem vyžadovány. Ale refaktoring kódu byl stále nutný, abychom se zbavili závislostí, které jsme nepotřebovali, jejichž graf bylo také potřeba podrobně prostudovat. Mimo jiné jsme opustili komponenty, které byly navrženy pro práci s ML: příkazy pro chytrou domácnost jsou jednoduché a strukturované, prostě zde nepotřebujeme těžké ML. Hrozilo také, že bude potřeba něco speciálně přepsat pro ARM, ale – naštěstí! – toto riziko se nenaplnilo.
Nakonec jsme dali dohromady vlastní verzi, která se vešla do 90 MB RAM a 73 MB flash paměti (někdy tomu láskyplně říkáme Behemoth).
Provedení příkazu
Nyní máme příkaz chytré domácnosti ve strojově čitelné podobě. Týmy mohou být velmi odlišné. A backend chytré domácnosti musí správně zvládat přejmenování zařízení, podporu různých místností a domů a mnohem, mnohem víc. Celá tato logika pro MIDI by mohla být napsána od začátku v C++. Ale za prvé to trvá dlouho a za druhé je synchronizace změn funkčnosti mezi lokálními a cloudovými komponentami obtížnější, pokud jsou vytvářeny nezávisle.
Existovala také alternativní cesta: vybudovat odlehčenou verzi backendu chytré domácnosti. V tomto případě by uživatelova konfigurace chytré domácnosti mohla být uložena na zařízení a synchronizována s cloudem ve stejném formátu. Znělo to skvěle, ale backend byl napsán v Go a spotřeboval více než půl giga flash paměti a téměř 200 megabajtů RAM. Nápad se nám ale líbil, a tak jsme začali přemýšlet.
Go je kompilovaný jazyk vytvořený pro ARM. Situace je jednodušší, než by mohla být s Javou nebo Pythonem. Pokusili jsme se zkompilovat binární soubor a spustit jej na platformě. Začalo to. Zbývalo jen zapracovat na jeho choutkách. Stejně jako v příběhu o Behemotovi začali ručně vyhazovat vše, co nebylo potřeba lokálně uložit na sloup. Například jsme opustili komponentu, která je zodpovědná za čtení hlasového senzoru reproduktoru, protože stále nemáme místní syntézu řeči. Díky tomu se binární soubor odlehčil a zrychlil (vešel se do 90 MB RAM) a úspěšně fungoval na Stanici.
Výsledek?
V Midi Station se nám podařilo vytvořit nejen lokální chytrou domácnost s podporou Zigbee zařízení, ale také dát lidem možnost ji ovládat hlasem. To je užitečné nejen v případě, že není internet. Místní proces vždy funguje pro příkazy chytré domácnosti, což znamená, že vaše žárovka Zigbee a jakékoli jiné kompatibilní zařízení se zapnou rychleji.
Zrychlení jsme měřili následovně: v některých testovacích reproduktorech jsme násilně zapnuli cloudový proces práce s inteligentním domem, v jiných – místní, a pak spustili desítky příkazů a vypočítali časování. Rychlost ASR do značné míry závisí na složitosti fráze, kterou je třeba rozpoznat. Rozsah výsledků je proto velký. Ale v průměru místní ASR fungovalo rychleji, i když ne mnohokrát. Ale s dalšími fázemi procesu je vše mnohem jasnější: místní Begemotik a UD backend se s úkoly vypořádaly v průměru 6krát rychleji než cloudová možnost (včetně kvůli absenci zpoždění sítě).
Dalším krokem je počkat na zpětnou vazbu od prvních uživatelů Midi Station, kteří ji využijí k ovládání Zigbee zařízení. Rád bych věřil, že uživatelé na vlastní oči zaznamenají rozdíl a potvrdí poptávku po novém řešení. co myslíš?

Pro domácího asistenta existuje skvělý místní hlasový asistent s názvem Almond.
⛔ Jeden přepadení – on Angličtina.
Tak to dejme tomu русский Hlasová asistentka – Irina.
S Malinou Pi1 B+ nefungovalo (důvod v ARMv6), zkusíme štěstí s Orange Pi PC 2 .


1. Připojte náhlavní soupravu.
* Testování zvukové karty.
— Přidejte uživatele do zvukové skupiny.
sudo usermod -a -G audio homeassistant
— Restartujte Raspberry
restart
— Díváme se na data na zvukových kartách v terminálu.
cat /proc/asound/cards
ls -l /proc/asound/card*

Můžete se na to podívat podrobněji.
lsusb
aplay -l
arecord -l
Připojení se provádí přes rozhraní ALSA (přístupový protokol):
hw:, – přímé spojení s hardwarovým zařízením.
plughw: — překlad ze standardního protokolu na protokol podporovaný zařízením.
⚠️ Zvukový server PulseAudio, pro tento případ není potřeba.
— Kontrola sluchátek USB.
test reproduktorů -Dhw: 1,0 -c2 -twav
— Kontrola mikrofonu (zápis do souboru out.raw) .
arecord -Dhw: 1,0 —format=S16_LE —duration=5 —rate=16000 —file-type=raw out.raw
— Přeneseme nahraný soubor do reproduktorů.
aplay -Dzásuvka: 1 —format=S16_LE —rate=16000 out.raw
— Výstupní zvuk z mikrofonu do reproduktoru ➡️ .
arecord -Dhw: 1,0 —formát=S16_LE —sazba=16000 | aplay -Dzásuvka: 1 —format=S16_LE —rate=16000
— Nastavte citlivost mikrofonu a reproduktoru.
alsamixer -c 1

— Ve výchozím nastavení nastavte kartu USB headsetu na ALSA.
sudo nano /etc/asound.conf
#Výchozí nastavení zařízení ALSA
karta defaults.pcm! 1
— Restartujte Raspberry
restart
— Kontrola výchozího provozu ➡️ .
arecord —format=S16_LE —rate=16000 | aplay —format=S16_LE —rate=16000
2. Hlasová asistentka Irina.
Opět hromada příkazů v terminálu (Při instalaci je vyžadován přístup IPv6.)
a.) Příprava.
sudo apt-get update
sudo apt-get upgrade
— Sdílené knihovny.
sudo apt-get install lame opus-tools flac
— Knihovny pro nástroje pro rozpoznávání řeči vosk
sudo apt-get install portaudio19-dev libjpeg-dev zlib1g-dev
— Knihovny pro hlasový modul rhvoice-wrapper, pyttsx.
sudo apt-get install –no-install-recommends build-essential python3-pip python3-setuptools python3-wheel libspeechd-dev libasound2-plugins espeak-ng
— Něco z toho je potřeba pro rhvoice-wrapper-bin
sudo apt-get install python3-gst-1.0 gir1.2-gstreamer-1.0 gstreamer1.0-tools gir1.2-gst-plugins-base-1.0 gstreamer1.0-plugins-good gstreamer1.0-plugins-ugly
b.) Instalace.
— Zavádíme administrátorská oprávnění:
sudo -u domácí asistent -H -s
cd /srv/homeassistant
— Vytváříme virtuální prostředí.
python3 -m venv .
— Aktivace virtuálního prostředí.
zdrojový zásobník / aktivovat
— Potřebné programy
pip3 nainstalovat scons lxml vosk rhvoice-wrapper rhvoice-wrapper-bin
— Propuštění klonu Iriny (Irene-Hlasový asistent-Mistr)
git klon github.com/janvarev/Irene-Voice-Assistant
— Nainstalujte požadované závislosti
cd /srv/homeassistant/Irene-Voice-Assistant
pip3 install -r požadavky.txt
— Spouštíme hlasovou asistentku „Irina“.
python3 runva_vosk.py

c.) Nastavení.
– Ukončíme program a v jiném okně terminál…
— Upravit nastavení systému core.json.
nano /srv/homeassistant/Irene-Voice-Assistant/options/core.json
“mpcIsUse”: true false,
“playWavEngineId”: “audioplayer” “aplay”,
“ttsEngineId”: “pyttsx” “rhvoice”,
Tady můžete změnit jméno asistenta (Irina).
— Kopírovat (cp) ze složky /plugins_inactive do složky /plugins
plugin_tts_rhvoice.py
— K vypnutí zbytečné rozšíření, přenášíme (mv) je ze složky /plugins do složky /plugins_inactive:
plugin_mediacmds.py
plugin_playwav_audioplayer.py
plugin_tts_pyttsx.py
plugin_tts_silero_rest.py
– Vracíme se do terminálu s virtuální okolí. Běh rozpoznávání hlasu.

– Ukončíme program a virtuální životní prostředí.
výstup
d.) Autostart ⚡.
— Vytvořte spouštěcí soubor.
sudo nano /etc/systemd/system/[email protected]
[Jednotka]Description=Irene-Hlasová asistentka
After = network.target
[Servis]Typ = jednoduchý
Uživatel = pomocník v domácnosti
WorkingDirectory=/srv/homeassistant/Irene-Voice-Assistant
ExecStart=/srv/homeassistant/bin/python3 /srv/homeassistant/Irene-Voice-Assistant/runva_vosk.py
Restart = vždy
[Nainstalujte]WantedBy = víceúčelová.target
— Aktivujte automatické načítání.
sudo systemctl –system daemon-reload
sudo systemctl enable [email protected]
sudo systemctl start [email protected]
Chatování s Irinou. ➡️
3. Integrace s Home Assistant
Existuje plugin, který vám umožní spustit scénáře Domácí asistent prostřednictvím hlasového ovládání “Irina” (požadavky se podávají přes REST API).
A. ) API token
— Od Home Assistant dostáváme token „Long-term API token“. (Autorizace rozhraní aplikace).


— Kontrola stavu našeho tokenu API (typ požadavku – GET) .
curl -X GET -H «Oprávnění: Nositel » http:// :8123/api/
“API běží.”

— Podíváme se na stav objektu lustru přes API token.
curl -X GET -H «Oprávnění: Nositel » http:// :8123/api/states/input_boolean.list
“state”:”off”

b.) Plugin Voice Assistant Irina
— Zastavte hlasového asistenta „Irina“.
sudo systemctl stop [email protected]
— Stáhněte si plugin_hassio_script_trigger.py a zkopírujte jej do složky:
/srv/homeassistant/Irene-Voice-Assistant/plugins/
— Spouštíme hlasovou asistentku „Irina“.
sudo systemctl start [email protected]
— Zastavte hlasového asistenta „Irina“.
sudo systemctl stop [email protected]
— Zkontrolujeme, co je ve složce /možnosti objevil se soubor s nastavením:
plugin_hassio_script_trigger.json
— Otevřete soubor nastavení ověřování API.
nano /srv/homeassistant/Irene-Voice-Assistant/options/plugin_hassio_script_trigger.json

— Opět upravujeme nastavení systému core.json
nano /srv/homeassistant/Irene-Voice-Assistant/options/core.json
“isOnline”: nepravda, pravda,
“logPolicy”: “cmd” “none”,
c.) Automatizace v Home Assistant
Zásada práce plugin – spouští skripty Home Assistant zapsané v skripty.
— Asistenta jmenujeme: Irene.
Může být nahrazen jiným v core.json
— Dále klíčové slovo pluginu: chci | udělat | budu.
Může být nahrazen jiným v plugin_hassio_script_trigger.py (řádek 25).
— Říkáme tomu poslední. název skriptu (ne nutně jedno slovo).
– v skript, můžete potvrzení změnit na ne standardně.
ttsreply()

Mluvíme.
— Irina Chci světlo.
— Náš lustr je zapnutý/vypnutý .
— Irina potvrzuje: Dokončit.
— Podívejme se na zatížení systému.
htop

— Jako zařízení se mi více líbí reproduktor Bluetooth.

– Prozatím použijte mikrofon na desce Nemám to v plánu.
Abych to shrnul.
– Žehlička není přetíženo.
— Lze použít na dálkovém ovládání server.
— Rozpoznávání řeči zapnuto vynikající úroveň
— Hlas rozhodně není „Alice“, ale docela kvalita.
– Všechny zbytek pluginy také práce .
PS*
– Sluchátka odpojeno, Takže всё vypnout.
sudo systemctl stop [email protected]
sudo systemctl vypnout [email protected]
sudo nano /etc/asound.conf
#Výchozí nastavení zařízení ALSA
#karta defaults.pcm! 1
restart